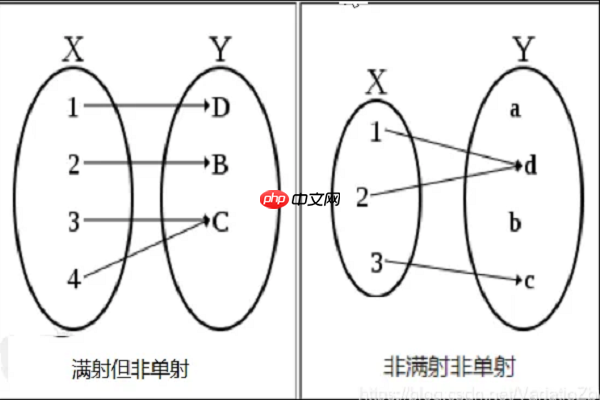
窗口函数保留原表行数并支持同行字段访问与有序计算,GROUP BY 压缩行数且仅允许分组键和聚合列;二者执行时机、逻辑层级及典型用途均不可互换。

窗口函数和 GROUP BY 都能做聚合计算,但根本目标不同:窗口函数保留原始行粒度,只为每行“附加”一个计算结果;GROUP BY 则强制压缩数据,输出行数通常少于输入行数。
计算粒度与结果行数不同
这是最直观的区别:
- GROUP BY 按分组字段合并多行 → 输出一行代表一组 → 行数 ≤ 原表行数(常显著减少)
- 窗口函数 不改变原始行结构 → 每行都参与计算,也每行都输出结果 → 输出行数 = 原表行数
例如对销售表按地区分组求总销售额:GROUP BY region 返回每个地区一行;而 SUM(sales) OVER (PARTITION BY region) 则在原表每一行后追加本地区的累计销售额,行数不变。
能否访问当前行的“同行其他字段”
GROUP BY 后的 SELECT 列必须是分组键或聚合表达式,无法直接引用非分组、非聚合字段(如 SELECT region, name, SUM(sales) FROM t GROUP BY region 会报错);
窗口函数运行在完整结果集上,所有原始列都可用:
- 可写
SELECT name, region, SUM(sales) OVER (PARTITION BY region)——name和region同时出现,不冲突 - 还能结合排序(
ORDER BY子句)实现累计、排名、前后行比较等,GROUP BY完全不支持这类有序上下文操作
执行时机与逻辑层级不同
SQL 执行顺序中,GROUP BY 发生在 WHERE 之后、HAVING 和 SELECT 之前,属于“行压缩层”;
窗口函数实际在 SELECT 阶段最后执行(甚至晚于 ORDER BY),它看到的是已过滤、已分组(如果用了 GROUP BY)、已投影的中间结果集 —— 所以你甚至可以在 GROUP BY 的结果上再开窗:
- 先
GROUP BY region, year算出各年各地区总销量 - 再用
AVG(total_sales) OVER (PARTITION BY region)算每个地区多年平均值
这种“聚合后再分析聚合结果”的能力,GROUP BY 单独做不到。
典型用途不可互换
有些需求只能靠其中一种实现:
- 给每条订单标出“该客户第几笔订单” → 必须用
ROW_NUMBER() OVER (PARTITION BY customer_id ORDER BY order_date) - 显示每个员工工资及部门平均工资差额 →
salary - AVG(salary) OVER (PARTITION BY dept),不能用GROUP BY因为要保留每人一行 - 统计每个品类销量占比(品类销量 / 总销量)→ 可用
SUM(sales) OVER ()得全局和,再除;若用GROUP BY就得两次查询或子查询,更重且难读
反过来说,单纯统计“各城市订单数”,用 GROUP BY city 更直接轻量,没必要开窗。