
首先启用浏览器内核模拟加载动态页面,配置翻页规则抓取音乐列表,通过分析网络请求提取音频直链及包含token的防失效机制,利用XPath或JSON提取器获取歌曲名、歌手、专辑等元数据并清洗,设置随机延迟、轮换User-Agen...
网站首页 > 火车头采集器
-
LocoySpider如何采集音乐资源链接_LocoySpider音乐采集的元数据抓取
-

火车头采集器如何提取JSON数据结构_火车头采集器JSON解析的嵌套提取
需配置JSON解析规则提取嵌套数据,先启用JSON模式并填写正确路径如data.user.name,数组用list[0].title,结合正则预处理非标准格式,最后通过测试验证结果准确性。 如果您在使用火车头采集器抓取网页...
-
火车头采集器如何优化CPU占用率_火车头采集器CPU优化的线程限制
调整采集线程数、设置请求间隔、限制并发任务及启用CPU预警可有效降低火车头采集器的CPU占用率。 如果您在运行火车头采集器时发现系统CPU占用率过高,导致电脑卡顿或任务执行缓慢,则可能是由于采集任务的线程设置不合理所致。以...
-
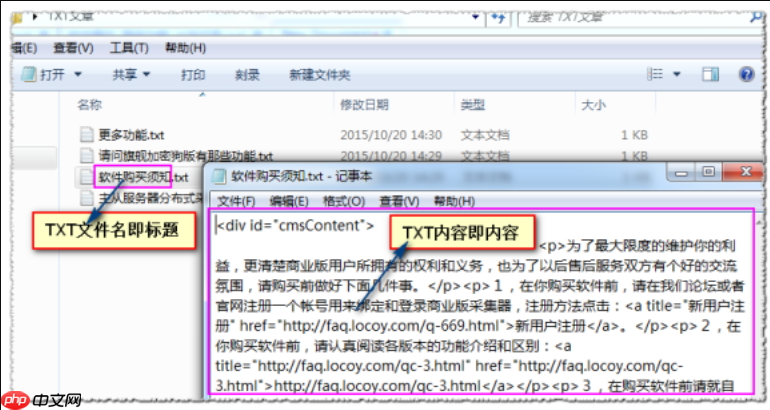
火车头采集器如何处理网站重定向_火车头采集器重定向的链接跟随
首先启用火车头采集器的自动跟随重定向功能,确保能获取3xx跳转后的最终页面;若遇JavaScript或meta刷新跳转,则需手动提取跳转URL并设置二级采集规则;同时通过添加User-Agent、Referer等请求头模拟真...
-

火车头采集器如何提取RSS订阅源_火车头采集器RSS源的定期更新
使用火车头采集器添加RSS地址作为起始网址,可自动获取网站最新内容链接;2. 配置定时监控任务,设置周期性采集并过滤重复网址,实现持续更新;3. 从RSS的XML结构中提取标题、摘要、发布时间等字段,通过前后截取或正则表达式...
-
LocoySpider如何采集房地产信息_LocoySpider房产采集的价格提取
使用LocoySpider采集房产价格数据需先配置目标网站及分页规则,再通过XPath提取详情页价格并用正则清洗,针对动态加载内容启用浏览器内核模式,最后验证数据准确性并导出为Excel或CSV文件。 如果您需要从房地产网...
-

LocoySpider如何集成机器学习过滤_LocoySpiderML集成的分类模型
可通过Python脚本、API服务或内嵌轻量级模型三种方式将机器学习分类模型集成至LocoySpider,实现智能化数据筛选。 如果您在使用LocoySpider进行数据采集时,希望自动识别和过滤无效或低质量的内容,可以通...
-

LocoySpider如何调试正则表达式_LocoySpider正则调试的匹配测试
答案:使用LocoySpider内置正则测试工具,通过粘贴网页源码、输入表达式并测试匹配结果,检查语法与转义字符,启用单行模式处理换行,利用多样本对比优化兼容性。 如果您在使用LocoySpider采集数据时,正则表达式无...
-
火车头采集器如何备份软件配置文件_火车头采集器配置备份的版本控制
可通过备份配置文件保留火车头采集器设置,避免重复配置。一、手动复制Data或Config文件夹至安全位置,命名时添加时间戳便于识别版本。二、使用软件内置导出功能将采集规则保存为.ltr格式文件,按项目或日期分类存储。三、结合...
-
火车头采集器如何监控网站变化更新_火车头采集器变化监控的差异对比
首先设置内容监控任务,通过火车头采集器新建任务并配置目标网址与采集频率;接着定义关键字段提取规则,使用选择器工具精准抓取标题、发布时间等核心信息;然后启用差异比对功能,系统将自动识别文本增删或数值变化,并标记有效变更;最后配...
1
2
